{kind=link}
{kind=link}
I get emails:
On 1/22/22 9:51 AM, XXXX wrote:
> Hi sorry to bother you,
>
> I'm a it enthusiast and recently I came across your name associated with some
> mirai sample.
>
> Can we talk about it?
My old https://landley.net/aboriginal prebuilt binary toolchains got used to build rather a lot of weird code over the years, including some old rootkit stuff, and those old versions of gcc leak the build path of the toolchain/libraries into the output. (The were uClibc based and glibc is incompetent at static linking, so the cross compilers you could fish out of debian with the qemu-debootstrap stuff were way less useful for making portable binaries.)
My toolchain got stale because I stayed on the last GPLv2 release of each package that went GPLv3, and I wound up fighting the linux kernel devs to revert stupid stuff (see the sources/patches directory on https://github.com/landley/aboriginal). I switched to musl-cross-make years ago but never posted binaries of those because I don't trust GPLv3 not to turn into a lawsuit without a large corporate legal department standing between me and the loonier parts of the FSF ecosystem.
(I keep meaning to try to convince github to build the toolchains and host the binaries for me as part of the build commit hook stuff, but I'm told NFT clowns abused that infrastructure for coin mining and it caps the CPU usage or something now? It's on the todo list to poke at it...)
Rob
Of course now that I've actually looked at microsoft github's workflow docs, it looks like they delete the retained output files after 90 days. So not a place to put stable links to release binaries. Oh well.
January 21, 2022
I should really get the next video up, it's been a week and a day. The problem's topic granularity: the next thing to explain is making a choot dir with the actual toybox --long paths, and that leads innto chrooting into it and going "ps shows nothing" and mounting /proc, and "ls -l has UIDs but not names" so making a simple /etc/passwd and /etc/group, and the problem is all that stuff is mkroot's job? Hmmm, I suppose a video on how doing is fiddly and deep, and then explaining how mkroot does it. But before talking about mkroot, I need to talk about building toybox from source...
Ooh, I think a contributing factor to the anxiety/queasiness is the matcha milk tea I found at HEB gives me an upset stomach. (Black tea doesn't, but raw tea seems to?) That's unfortunate -- it's very tasty -- but the timeline lines up. One way to find out...
I finally found an online japanese teacher I like (Cure Dolly). Pity she died in october. I was pretty sure the voice behind the CGI cartoon was a little old lady, but the RIP entry on her patreon kind of confirmed it. Still, the youtube videos are up, there's a blog, and she wrote a book. Lot of good work there I can benefit from.
Her estate manager posting about taking the patreon down (and having to manually hit "skip billing this month" each month until then) does highlight the archival format problem again. Ten year old clever essays on livejournal are still there (at least the ones that survived strikethrough) despite the russian mafia basically owning that site for over a decade now, but patreon can't stop charging people money and still retain the content with monthly manual intervention. Everything there is inherently ephemeral because capitalism.
Paid for a rideshare to the big fedex office on guadalupe to finally get that box mailed back to previous $DAYJOB. (The third machine they pointed at the QR code understood it.) Then since I was already 2/3 of the way to the philbin I walked there and hung out in the office space current $DAYJOB is paying for. The experience is profoundly mediocre. Today I noticed that the wifi is plaintext. They have a web page you have to log into to access net through them, but the first hop to the router is unencrypted so everybody in the Dobie Center, one of the largest dormitories in the middle of the sixty thousand student University of Texas main campus, can trivially snoop anything that goes by on a non-https link. Starbucks was already encrypting its wifi in 2006. Sure it's not MUCH protection but the equivalent of listening in via police scanner seems... not thought through?)
I asked at the front desk: connecting to wifi with a password is something they want you to pay extra for. Capitalism again. I'm back to using my phone tethering with the USB cable. Yes everything I access is presumably already encrypted and this extra outer layer is permeable with enough effort, but I don't want have to WORRY about it and I'm insulted they perform a task incompetently for the lower tiers and want to charge extra for performing the exact same task with minimal competence. (There's an ethernet jack on the desk, but I didn't bring a cat 5 cable.)
So far the advantages of this place over the table outside the geology building (or the seats in the biology building courtyard, or...) are:
- it's not so cold late at night
- hot water you can make ramen cups with
- the bathroom is closer
- fewer flying insects on warm days
On every other metric, it loses. Starting with "hours of access".
January 20, 2022
Huh, my blog is unsearchable on Google again. I tried explicitly searching for which year I first blogged about the three distinct failure modes that open source user interface development breaks down into (because somebody complained that VLC's wanted to add a video editor front-end forever but never has: that's the "separate engine from interface and hope an improved interface shows up by magic one day" failure mode)... and my blog didn't come up. Not when I quoted "landley" and not even when I added site:landley.net. I had to grep the files locally on my laptop to find that link.
This is probably related to Google popping up a "show simplified view?" thing when I look at my blog on my phone. I'd blamed android update du jour but it seems to be Google search policy changing again. My blog is hand-coded html in vi using a half-dozen tags all from the 1990s (mostly p, a, h2, hr, pre, and b with the occasional completely ignoreable span I keep meaning to teach the rss feed generator about). There is no stylesheet. How exactly do you get "simpler" than that? (And yet the android browser has consistently displayed <pre> blocks in the smallest possible font for years, rather than the same font size as the surrounding text. That's not an Android 12 bug, that was already broken back when I had a Nexus 5.)
Oh well. Google isn't ready to go the way of Sears quite yet, but it's clearly no spring chicken anymore. Constantly losing capabilities it used to have, even if the stuff it nominally decides to keep. (It's ironic that the Google Graveyard I prefer to link to is not the CURRENT google graveyard. It is in fact currently the 7th hit on Google for "google graveyard".)
Sadly, this is another example of large companies favoring centralized sites instead of distributed ones. Google can find twitter. Another blog entry I did years ago was about the Linux Foundation providing a "face" for linux (single point of contact) the way AOL provided a face for the internet back in the 1990s. Neither was ACTUALLY representing what it claimed to, but as with a man repeating a woman's words in a meeting and getting credit for it, they successfully stood in front of the real thing, took credit for it, and got all the attention/control/funding. (Pretty sure google wouldn't be able to find that blog entry either.)
January 19, 2022
Today's high was 81 degrees, and it's supposed to get down around 20 tonight. (For the rest of the world, that's just over 300 kelvin to 266 kelvin.) Not going to the table tonight.
The recently ended job finally emailed me some RMA authorizations, so I packed up the hardware I had from them into a box and taped the printout to it, and instead of dumping it in an unmanned drop box I carried the box a mile north to a walgreens with an actual human in it representing fedex (well, eventually)... who couldn't cope with the QR code the email attachment printed, nor could they accept actual money to mail the box. (They're just a drop-off point, I'd have to go 2 miles to find a real fedex with humans working in it.) In theory fedex can pick up from my house, in practice they require a credit card to set up an account to do that. Try again tomorrow, maybe the location on guadalupe just north of UT can deal with this? I could hire a taxi-equivalent. (Alas the loony governor who eliminated gun permits and registration destroyed the cab business 3 years ago. Lyft is... less evil than uber I guess. I had the rideaustin.com app installed on my phone at one point, but they didn't survive the pandemic, the "temporarily closed" on the website was 2020 and they made it official 3 months later. And of course Austin's last surviving cab company was bought by an app I've never heard of and won't be using.)
*blink* *blink* The tables at HEB are near random televisions showing news or sports or something (I have headphones, don't have to listen), and a commercial came on with a countdown telling you to do nothing for 15 seconds. It's apparently advertising the "calm" app. People need to not just be told to do nothing, but walked through how? Really? And some for-profit entity has decided to attempt to monetize that?
Today's android 12 bug: the recent update has made the phone come on in my pocket multiple times. Fade called and said she got "road noise" while I was walking home with the box fedex wouldn't take. Walking home from the HEB later I pulled out the phone to look something up and the flashlight was on, with the screen on and deep in the pulldown menus. Still later, I pulled the phone out and the screen was on in the google play menus at the "do you really want to disable play protect" confirmation prompt. One of these navigated slack into the info menu of the general channel when I switched to that app.
I think what the update broke is the proximity sensor that disables the screen when you put the phone against your head during a call. It's not noticing it's in the pocket, and the random walking motion of pocket against screen is apparently enough to swipe up sometimes and get out of the just-came-awake screensaver panel, and then do random things with the resulting icons. Alas, I can't cherry pick JUST the parts I want out of any of these "updates", it's all-or-nothing lateral progress where they broke random new stuff each time...
Charles Stross explaining to a reader how to get an unecrypted version of one of his e-books is a good example of bit-rot: this used to work and it stopped working because of a combination of version skew (gratuitous upgrade to python3 breaking existing code that worked fine) and late stage capitalism closing up yet more stuff to corner the market harder. This too shall pass.
I like to tell people that the corrolary of Moore's Law is that 50% of what you know about the software stack is obsolete every 18 months, and the great strength of Unix has always been that it's mostly the SAME 50% cycling out over and over, a reef of C and posix with waves washing over them. It's not immortal, but outlasting the competition has been quite the recipe for success over the years.
January 18, 2022
On Fade's advice (she's been dealing with anxiety for decades and I'm new to it; I had about 15 years of depression but usually not anxiety) I took an ibuprofen and melatonin last night, and did manage to get some sleep. Still under the weather. The second time Jeff got Covid in japan (South Africa variant at the time, now renamed "megatron" because mentioning geography is racist) he had several days where he was anxious and couldn't sleep, so I'm wondering if this is Omicron manifesting through two rounds of J&J and two previous infections? (Annual flu vaccine doesn't stop you from getting the flu, it just makes it suck less when you do. Fade pointed out you can order 4 of Biden's covid tests now, for delivery "eventually". If I had one I'd probably take it.)
Another long design call with Jeff (this time going through the open source ASIC toolchain build stuff: instead of feeding ghdl+yosys output into icestorm, you use qflow and magic and spice and so on), and I was wondering why I was out of brain after only 3 hours... turns out we'd been talking for almost 4 and 1/2. (I have a duration readout for the current call, but I hung up and called back to use wifi instead of my cellular bandwidth, and I thought the first call was only an hour when it was almost 2. Right, that explained it.)
So many toolchains: I build Linux with the sh2eb-fdpic one from musl-cross-make, which comes in cross and native. Jeff insists we need an ELF one to build a bare metal BSP toolchain around. (Speaking of which, picolibc is my new example of how horrible bsd-style license combinations can get, and I quote: "There are currently 78 distinct licenses: 10 versions of the 2-clause BSD license, 37 versions of the 3-clause BSD license, and 31 other licenses.") Then there's the open source GHDL+yosys+icestorm FPGA toolchain targeting Lattice ICE40, or it can output a netlist that we can feed into xilinx webice (swapping out the front-end lets us use a newer VHDL standard than that old xilinx toolchain natively supports). And today's talk was about an ASIC toolchain that produces a mask for the fab, from a LOT of inputs through a LOT of stages and then testing it is... horrific. (The "spice" current flow physics simulator did not blossom under 30 years of Moore's Law the way the rest of the tools did.) There was also a proprietary lattice toolchain but it was crap and we've fully replaced it with the open source one. Someday I hope to have superh support in llvm.
Speaking of the ice40 bitstream toolchain: I got my build script to build the new packages with the new options in the new order, and sent it to Jeff again. The build isn't QUITE producing all static packages: icestorm seems to be ignoring the STATIC=1 option now? It's still there in the plumbing. I may need to bisect for the last version that worked with STATIC=1...
But I should have a new snapshot to upload before long. My login credentials to j-core.org went slightly stale: my ssh key gets me in but the login shell reset to /bin/sh (and thus the Defective Annoying Shell which in this distro doesn't not implement tab completion), and I had to zap the ssh host key because of whatever reinstall it went through when Wale fiddled with the VM. Sigh...
In theory I can also have it build nightly on my tiny server, and then build the J1 repo and run the simulator and catch regressions. That's a todo item.
January 17, 2022
Did not sleep at all last night. Lay awake in bed stressed. Took advantage of the holiday to stay in bed until almost 1, but it didn't result in any more sleep.
Jeff did a new VHDL toolchain build script based on the script he did a couple years back, completely ignoring my rewrite that made it do things like "git update when the repositories already exist instead of git clone", and "allow the build to happen without net access from a known set of local sources rather than trying to git clone the abc repo in the middle of the yosys build", plus the config checks to autodetect whether you have gcc or clang, and use readline if it's installed but don't if it's not... Oh, and of course preventing one of the package builds from calling "git clone" of a subrepo in the middle of the build (by downloading it myself as one of the packages and symlinking it into the build where it goes, so it's an actual tracked and updated package instead of re-downloaded mid-build each time. That's kind of important. And statically linking all the binaries so the resulting directory can be tarred up and used on an arbitrary target system... I did a lot of cleanup and productization work on this build.)
So I've got his new build script (replacing the "beta" package that was kind of sideloaded into yosys with a final package that's more integrated and called a different way), and I've got my old build script, and I'm trying to hammer them together, but I still don't want to run big builds off of battery because my laptop can suddenly power down even with 50% battery left. (It's only done it twice, but it left an impression.) Yeah, I can taskset 1 the build to force it to use just 1 CPU. (Or taskset 3 seems manageable, which contrary to first impression makes it use cpu 2 | cpu 1.)
Not a hugely productive work day with no sleep and "don't think about a purple elephant" anxiety avoidance strategies. (Plutocracy has cornered the market on spending money, not just collecting a fee every time but passing value judgements about what you are and aren't allowed to spend money on, starting with the nominally indefensible and spreading out from there the way the first nazi bookburning in germany was the library of a gender studies institute supporting trans people 100 years ago, hindsight about which is what inspired the "first they came for" poem. Since the dollar is the global reserve currency, we're exporting this "table legs need stockings covering them because otherwise it's indecent" lunacy to other countries. And we can't even focus on this with late stage capitalism pricing everyone out of their homes, a school-to-for-profit-prison pipeline bypassing the 14th amendment, student loans immune to bankruptcy with loan forgiveness being the new pie-in-the-sky dangled in front of people but never delivered by the octagenarian president, the retirement age endlessly increasing as lifespans decrease... Right, don't think about any of that until I can be ANGRY again rather than scared about living in the christian version of saudi arabia.)
January 16, 2022
Stomach bug today, which makes me wonder how much of yesterday's stress was "my intestines are clenched up" reading as stress. (I'm still pissed about all those issues, but I usually get on with things better.)
Looking at a todo list dated December 2020 and going "eh, only a month old" is a "still writing wrong year on my checks" variant. It's "twenty twenty also" already, the whole year "twenty twenty defeated us" was in between...
Android 12 had a system update last night, and now I actualy CAN summon the nav buttons at the side of the screen when watching a fullscreen netflix video! (In a non-obvious way, it's not drag up it's drag from "guess which side it thinks is the bottom" but at least there's a WAY to do it again.) I don't know if this is because the update changed my settings from "always show the darn buttons" to "smartass hiding" again, or if they actually fixed something. I'm just happy not to be faced with it today and am not lifting up that particular rock to see what's under it right now: BUSY WITH OTHER THINGS...
(That said, since the update youtube has decided to freeze and restart itself twice, once with one of those minimized windows jumping halfway across the screen when I tapped on it and another ignoring the nav bar of a video until I hit the "back" button at which point it started replaying the video from the beginning? Wasn't doing that before that I'd noticed. So yeah, they moved the bugs around but getting the nav buttons back is a net win.)
I broke down and sent Version 4 of the CONFIG_DEVTMPFS_MOUNT for initramfs patch to lkml. Debian's had four years to fix its obvious big so I didn't include the workaround this time, but the reason I'm doing this now is I'm using this patch and may wind up shipping it, and I like being able to point where I sent a patch I'm using to lkml and show THEY decided not to merge it when litigous assholes contact me about GPL issues. (Oh, feel free to open that can of worms, I'm pretty sure I can create a PR firestorm to cut GPL usage in HALF given a good excuse like "the guy who started the busybox lawsuits can't escape getting sued". Let me tell you what the FSF did to Mepis and here's a lovely sound bite from the Samba maintainer lamenting how the move to GPLv3 was a mistake in a recorded technical talk, here's the sound bite version of why I left busybox (and the lwn coverage of it for reference), and here's my soundbite about GPL from the 2013 ELC talk, and the "rise and fall of copyleft" talk I gave at Ohio LinuxFest, now let me tell you about 0BSD and the massive decline in GPL usage that motivated the need for a replacement for copyleft... Anger is depression turned inwards, not entirely sure where anxiety gets filed (I'm fairly new to dealing with it) but I admit looking for a "noble cause" (I.E. punching bag I can justify to myself) is tempting. Bad impulse, I know. But if somebody wants to present themselves gift-wrapped...)
Anyway, posted patch upstream so as NOT to incite such. I wasn't the one who started things with GPLv3 either.
The reason I'm fiddling with this patch is the Turtle board has an unhappy trying to run the script to mount devtmpfs itself, because some variant of nommu and that kernel config (or maybe real serial having different tty characteristics from qemu's?) is triggering some error handling path that isn't dealing with low filehandles right. Toybox lib/ has a "notstdio()" function that does a while (fd<3) { int fd2 = dup(fd); close(fd); open("/dev/null", O_RDWR); fd = fd2;}, and xopen() and friends all use that under the covers so things like "tar" aren't going to interlace -v output with the archive being generated even if called with no stdin/out/error. But this cleansing step should NOT happen anywhere in the toysh file handling path because we DO want the special case of init being called with no filehandles so mount devtmpfs and exec redirect stdin,out,and err to /dev/console. Which mkroot is doing and it works on the OTHER architectures... but not on turtle.
I need to properly debug this, but I also needed to get Jeff a usable root filesystem he can rebuild from source LAST WEEK, and keep getting interrupted by other things. Rich gives us filesystems even he can't easily reproduce, because there was no build: he hand-assembled it and keeps adding to what's there over the course of an entire project. I have mkroot building a clean vmlinux+initramfs entirely from source with the ability to overlay arbitrary stuff in a reproducible manner... and it crashes on turtle instead of giving a shell prompt. Frustrating.
I sent the patch to Rich asking him to add it to his linux-sh turtle branch, and he said his branch isn't for the purpose of overriding the kernel maintainers' judgement. Dude, patches OFTEN take years to get merged. My "three strikes and you'r out" was because _I_ got tired of dealing with the insular kernel clique. They were waiting for Debian to fix their bug. "It got posted and nobody noticed/replied" is 100% normal for linux-kernel, and conveys zero information. Probably what'll happen to this one too since I didn't run get_maintainers.pl and cc: 37 random historical people who haven't been involved in years. I got cc'd by Andrew Morton on an madvise patch this week, and have been chronically cc'd on Moudy Ho's mediatek patches for months, and this is DESPITE years of distance from linux-kernel. Back before git, people were literally setting up cron jobs to resend to Linus. (The proper fix was to switch to git and formalize the hierarchy of subsystem maintainers patches go through on their way to Linus, but I had to "don't ask question: post errors" to jolt people out of the cron job orbital they were stuck in.) This patch hasn't been resubmitted recently because I'M the one who got tired of dealing with it.
So I'm maintaining my own Turtle tree now. I need to upload that to j-core.org...
January 15, 2022
The german police used the EU's covid tracking app to track down witnesses to a case unrelated to covid. This is why I buy things with cash whenever I can: I don't want every purchase I make tracked and sold to anyone who wants to buy a copy, and of COURSE governments buy collected data from advertisers.
I'd like to link to a long informative thread about the new comstock act puritanism taking down more sites, but unfortunately twitter just stopped being a public website. If you scroll down in somebody's feed without being logged in, about 4 tweets down you get a full-screen modal pop-up "you must log in to read more" without any dismiss option, and even if you "right click->inspect element->delete node" to force-dismiss the pop-up the javascript has disabled the scroll bar so you can't go further down. (There's a way to inject javascript "enable scroll bar" into the page using the debug functions, but there's like 3 different ways they could have disabled it and... I can't be bothered?) I can still read the website on my phone's browser, but twitter is dead to me on the desktop.
Here is the "tumblr safe version" of the famous 1896 painting by French artist Jean-Léon Gérôme, "Truth Coming Out of Her Well to Shame Mankind". The original can still be on wikipedia because that site is not supported by advertising. AO3 has been explicitly defending itself from this censorship for years.
During prohibition, the US dollar became a currency you couldn't buy alcohol with, and rule of law basically went away. The gerontocracy has now made the US dollar a currency you can't buy legal things in anymore (still clamping down on cash), which is really obvious when there's something to compare it to. The "any rando can sue a woman who MIGHT have had an abortion in texas" which california's copying to sue gun manufactuers was pioneered by Fosta/Sesta. The gerontocracy has forgotten the concept of catharsis, that not everything worthwhile is healthy or pretty.
On balance, the kids are all right, the adults are wrong, and the geezers are wronger. Every time, in every society, throughout history. As they enter their second childhood, the Boomers are reshaping the world into 1950s drudgery. We even have a prominent political McCarthy lying in congress again.
The problem isn't just the fuzzy line where "I know it when I see it" is banned, it's risk-averse vendors self-censoring, and nobody is as risk-averse as Fortune 500 corporations. A lot of adjacent content is still there from years ago, but probably couldn't be posted today, and the situation looks to get worse before it gets better.
Youtube doing things like destroying reaction channels is just a sign of youtube declining, but the gerontocracy is a larger social problem that's corrupted the financial system. Capitalism itself is a problem now. Capitalism stands between people and how they want to live their lives. Capitalism punishes cooperation even though nature is full of cooperation. Like royalty, society has outgrown late stage capitalism which now serves a small and declining number of royal persons whom society would be much better off without, while the majority of the population are exploited and treated as a problem.
This is not stable. The traditional responses from the rank and file range from general strike through malicious compliance, and of course for gerontocracy simply letting the geezers die. The ongoing health care system collapse is rapidly reducing life expectancy in the USA. Preventative geriatric medical care was already failing to keep up with boomer demand but now it's simply no longer widely available. Not just the general health care shortage increasing the mortaility of heart attacks and cancer and car accidents, but "keeping Boomers alive longer" is not what most people want to do with their lives anymore. There were around 2 million elder care workers in 2017, declining to around 1.5 million at the start of the decade, and since the start of the pandemic elder care staffing has declined by 220k workers. Of course AARP estimates that 20% of the population is providing unpaid amateur elder care, which tends not to be sustainable for individuals to do long-term. Multi-generational households provided care for kids and elderly at the same time, these days who can afford to have kids, let alone a house that big?
Speaking of Boomers refusing to look in a mirror (I.E. objecting to teaching "critical race theory"), the number of murdered children found under canadian boarding schools is approaching five digits. There were 130 such schools and they've fully searched 6 so far. Remember how the germans sent teams to the USA in the 1930s to study american racism? Columbus bumped into a continent with something like 130 million people living on it. There are about 4.5 million left in the USA and 1.7 million in canada, both due to centuries of centuries of genocide. Yes, that was a link to two prominent american presidents personally responsible for native genocide, here's a third. The civil war didn't even slow DOWN racism against everyone else. Custer's Last Stand was a Union Brigadier General going out to murder native americans because the USA didn't feel like honoring its treaties and had leftover military resources from the war, which we turned west to clear land for cattle (and thus cowboys): the entire "wild west" was made possible by racist genocide committed by the NORTH after the war. (Hence Boomers playing "cowboys and indians" as children: it was still within living memory.) The Chinese Exclusion Act was passed in 1882. Hawaii was conquered by mercenaries from the Dole pineapple corporation in 1893. The USA rounded up japanese americans (but not German or Italian) and put them in concentration camps by executive order of president Roosevelt in 1942. Here's George Takei (Sulu from Star Trek) talking about his childhood in an internment camp for his ted talk.
January 14, 2022
My Android 12 bug workaround for getting the "back" button out of a reclacitrant app is to use the pull-down menu, hit the gear, and then the menu app listens to rotation and can thus give you back/desktop/applist buttons. EXCEPT when you're already _in_ the pulldown menus, doing the network & internet -> hotspot & tethering -> usb tethering dance to access the control that WAS available with a long press from the "hotspot" pulldown button until they "upgraded" it away. Unfortunately if you went there from a widescreen video, and have now attached USB tethering, you can't exit OUT of the tethering menu without a "back" button, so I have to physically pick up my phone and tilt it despite my USB cable being worn out enough it tends to disconnect if I do that.
Meanwhile, my old "make initramfs honor CONFIG_DEVTMPFS_MOUNT" patch broke because this patch removed the argument from devtmpfs_mount(), which seems REALLY stupid except... it says it was already broken? What?
Queue debugging rathole (test it under mkroot!): I was worried for a bit that "mkdir sub; mount -t devtmpfs sub sub" would try to mount it on /dev. (Mounting devtmpfs in a subdirectory is perfectly legal and a fairly normal part of setting up a chroot or container, doing the stuff requiring root access before you chroot into it and drop permissions)... but when I list it, it's there. And THEN I was worried it hadn't recorded the destination properly (which would screw up df and umount -a and friends), but... no, seems to still work? Ok, it looks like the argument it removed was the SOURCE not the destination. Ignoring the 'from' address in a synthetic filesystem... is acceptable: if it's not using it then sure. Before (circa 2013 when I implemented initmpfs) it was just being passed along and recorded as-is, and now it's hardwired to "same as filesystem type". Right...
I'm still subscribed to the coreutils list but haven't set up a filter and folder for it yet, meaning stuff posted to it winds up in my inbox (where I delete it). I ALMOST replied to one of them, but decided against it because I'm not really a part of that project and going "in toybox I did..." seems rude. But what I wrote and then deleted was:
I made toybox's dirtree plumbing use openat years ago and the subtlety of purely directory local operations is somebody can do a "mv" of the directory you've descended into so "cd .." will wind up somewhere else, so a pure descent counting strategy is insecure. And keeping a filehandle open at each level means you hit filehandle exhaustion when dealing with arbitrarily deep directories[1] so what I wound up doing (at least for rm) was having a structure with the name and stat() info of each directory I've descended through and then when I "cd .." back up into it I'd re-stat it to make sure it was the same, and if not either fail out or descend back down from the top using the names.
[1] The default ulimit -n is 1024 filehandles per process, but posix says ANY limit is unacceptable because rm -r needs to handle anything, because even in the days of MAXPATH you could (mkdir a/a/a/a/a...; cd a/a/a/a/a... mkdir ~/b/b/b/b/b....; mv ~/b .) and then repeat that moving the top "a" to the bottom of a new MAX_PATH stack to make an arbitrarily deep path.
Which once again reminds me that tests/rm.test needs a test for zapping paths longer than 4k, which is queued up for my "tests within mkroot" because I dowanna play with that sort of thing on my host system.
I also truncated a reply to the toybox list, because I _do_ usually blog about this sort of thing rather than posting it there:
As David Graeber pointed out, our current system thinks that "your life has meaning" is a form of pay, and that you should only ever need a financial incentive to do something you don't want to see happen. He wrote at least two full books about this, The Untopia of Rules and Bullshit Jobs. (Three if you count "Debt: The first 5000 years".) And he gave a bunch of interviews.
I'm very happy to have supporters on patreon. I'd love it if that could pay my mortgage. But I've spent my entire career going for "useful/interesting work" over "lucrative", and the question has always been been "how much useful/interesting work can I afford to do before I have to go earn money instead".
The well-paying jobs I take are not BAD jobs. (I turn stuff I really don't want to do down before even interviewing.) Tuesday a recruiter asked if I want to work on a medical device (18 month work-from-home contract), and I could see myself doing that if I was on the market. But I could see any random CS graduate doing that too, they don't particularly need ME to do it.
The "pays really well" job I turned down earlier this month would have paid what I owe on my mortgage in about 14 months. (Admittedly pre-tax and ignoring all other expenses, but probably about 2 years to pay it off realistically. I feel guilty for NOT taking that job, it's irresponsible to work on FUN technology when I could be effectively securing my retirement... but I burned out badly just trying to stay at the recently-ended contract for 6 months, and still have a backlog of stress and anxiety from that. Touch gun-shy of jumping into the unknown again quite so soon, and I'd owe them my best. I'm not currently at my best.)
If I'd stayed at JCI I'd already have paid my mortgage off by now, but the project I was interested in there ended and the new one they transferred me to was a large team doing yocto with systemd on an SMP arm board with gigs of RAM and hundreds of gigs of storage that they really didn't need me for. The Google recruiter du jour trying to get me excited about "20% time" last week had the problem that (according to The Atlantic) it became "120% time" ten years ago, but the bigger problem is that I'm already DOING that. Context switching between projects stops me from doing "deep dive large block of time intense focus" things, which is pretty much what's LEFT on toybox. I've been picking low hanging fruit for years, what's left is mostly hairballs, and the SIMPLER of those are things like "rewrite lib/password.c and change 7 commands to use it at once before you can check any of it in". That one's not conceptually hard, but still a big flag day change, plus rechecking the "to libc or not to libc" reasoning confirming the justification of the new plumbing's existence. (I walk away from that sort of thing and revisit it periodically doing an "eh, do I still agree, did I miss anything..." I agonized similarly over doing dirtree.c instead of using fts.h out of libc, back in the day...)
To be fair the coresemi stuff swap-thrashes out my toybox/mkroot headspace too, but since j-core is another thing I would like to see succeed in the world (which I've already spent years working on), it's still worth doing to me even if it's "instead of toybox". And I've usually gotten more than 20% time to work on toybox from coresemi, since they use it in their products.
Jeff Dionne's also paid for a lot of work hours from the musl maintainer over the years. Jeff not only did uclinux, but back in the day he was Erik Anderson's boss at lineo and thus started the ball rolling on both busybox and uClibc, although Erik continued those projects on his own initiaitve for a long time, and my involvement started after Jeff's had ended. (Unlike the earlier history with Bruce I did know that uClibc had spun out of uClinux, but at the time didn't really know what that WAS. Now I know it was the initial port of Linux to nommu hardware; it needed a userspace because most gnu packages couldn't cope with nommu, and thus sort of became a distro but that was never really its intent.)
I still learn a lot working with Jeff, which is the real incentive to stay. The money is just barely enought to _allow_ me to stay.
January 13, 2022
I got my first toybox video uploaded to my website yesterday, and informed patreon about it. It's a good single take but otherwise unedited, so I'm poking at blender as a linux-friendly video editing solution. That's looking like a truly enormous time sink to properly come up to speed on...
Fade flies back to her doctoral program on friday, so I've been doing some stuff but NOT trying to disappear down a technical rathole for 10 uninterrupted hours just now. That said, I'm trying to ping the toybox list more about my design pondering, because blogging about it has had an editing and posting delay long enough other people can't really react to things before I've done them. (Although for the moment I'm mostly caught up, in part because my patreon made it to the SECOND goal so I should definitely clean up my performance of the first goal: keep the blog updated.) And as I said, I _do_ try to get the bikeshedding out of the way up front. :)
I switched to mostly blogging about programming rather than posting it to my lists after the third-ish time dreamhost punched giant holes in the web archives (see yesterday's "databases inevitably go away"), and while I do have all the posts in mbox files it's split among three different places: the list mbox, my inbox, and my outbox. That fragmentation happened because gmail's done filtering I don't want and have never managed to disable for a dozen years now, which scatters data and breaks threads. To reconstitute it, I'd have to write a program to parse those three mbox files, extract messages to: or cc: the mailing list (oh and some of the messages were cc'd to OTHER lists too so I need to check ALL the mbox files to be safe)... It's not that hard to whip up a python program to do it, I just haven't spent a weekend on this. (And then if I DID, what would I do with the result? Put up my own archive directory somewhere and keep it updated?)
January 12, 2022
Ok, I need to get off of gmail NOW. The net-nanny software has made it unusable.
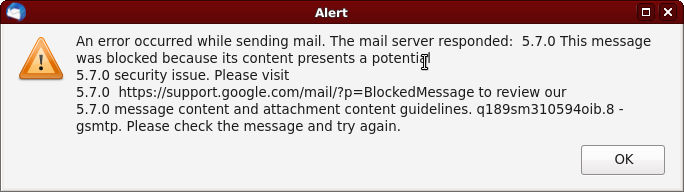
I was trying to send co-workers a tar.gz of an old right click -> save as snapshot of an internal wiki page about GPS timings over a homemade hardware bus, now that database has gone the way of all databases. (Seriously, we knew about the archival format skew problem thirty years ago; even when you THINK you have backups, new programs can't read old nontrivial formats. Nothing stored in a database is going to be usably retreivable ten years later unless somebody's dumped the output to a real static self-contained storage format, and even then half the time your PDF is a cover page with no contents or an index into a backup system that no longer exists.)
But gmail is doing a net-nanny thing: "oh no, I don't like the contents of that tarball, it's got css files and javascript in it, you're not ALLOWED to send that tarball". I didn't ask it to, and can't STOP it.
This is not a receive spam filter, this is a SEND spam filter. I am not allowed to SEND that email because gmail won't let me. It doesn't properly understand the contents but THINKS it MIGHT be dangerous, and insists it knows better than I do what's in my interest to be allowed to send. It had to decompress the file and untar the file (not a format widely used on windows) in order to scoff at the contents of the file. And note how there's no "here's how to override it", the linked page is "Here is an explanation of why you shouldn't have tried to do that in the first place you naughty child you.".
This is not a service I consider usable anymore. This is not a relationship I want to have with a service provider. Dreamhost provides mail servers as part of its service package, I just hate moving my email because my preferred recovery mechanism for stuff IS email. Grrr... Dowanna, but... really need to.
January 11, 2022
At this point, everything the Boomers touch turns to crap. We're not going to pry their hands off of anything, they're going to destroy it and we'll build a new one from the rubble when they die.
Sadly, this includes the health care system. Texas is redeploying the morticians who perform autopsies to work in the intensive care units; people who have never seen a living patient in their professional careers but are technically qualified to perform surgery, therefore can monitor a pneumonia patient. (Hospitals are bled dry and the Omicron surge is worse than Delta because it spreads faster and infects more people at once; doesn't matter what the average case is like if now is a really bad time to get a heart attack, or cancer, or appendicitis, or an abcessed kidney infection, or in a car accident, or have a fall, or... And of couse, what are we spending money on instead of healthcare? Not forgiving student loans, of course...)
The Boomers are dying in a mushroom could of racism, hypocrisy, and historical revisionism. Can we all just agree that IP law needs to die with the Boomers? Capitalism isn't looking good either. Capitalism is was always self-limiting but add late stage Boomer failure and it starts taking down countries: apparently the mess in Khazakstan is bitcoin's fault. And a lot of the money laundered through there was used to Lobby the US government capitalist gerontocracy.
Boomer Media continues to circle the drain. Did you notice how Boomer news stories are sponsored now? Not just by showing commercials, but in the content: the coverage is spun to advertise some random company used as a nominal example for issues the company in question is always trying to profit from. Because Boomers can't conceive a capitalism NOT being the solution to any problem.
Covid is being hugely underreported. The great resignation isn't just people resigning or finding better jobs, a lot more are dying: deaths from all causes are up 40% from pre-covid levels, with many people dying months AFTER having covid. Not just retirees but line workers exposed to the public and to office environments crammed in with a bunch of other people. (This is the life insurance industry wringing its hands over massively increased payouts, so "who is covered" skews the numbers. In addition to the elderly being really expensive to insure, why would a Boomer want life insurance? They're not the one it would pay out to.) On the bright side, vaccines don't just protect against immediate death from covid, they mitigate long covid.
Mozilla's desperate plans to fund itself with bitcoin are so bad the people who actually wrote the software have publicly come out against the company. Meanwhile to nobody's surprise, the cloud remains fundamentally insecure.
The cop mayor of NYC needs to be defunded out of office.
January 10, 2022
Got up bright and early and so I could walk to the Philbin this morning to have a 10am call with Jeff to try out the new collaboration setup to work on the J1 asic. Except they don't open until 8:30 am and I set out a bit early so I hung out at HEB for a couple hours first (the tables there are a lovely quiet work environment early in the morning and they have purchaseable caffeine), then walked home to heat up a can of coffee and roll it down an incline at Fade at her alarm time (she visited Japan years before I did and fell in love with the vending machines; I do my best to simulate the experience), and THEN walk to UT just in time to make the call with Jeff.
We wound up on the phone (eh, Google Meet + a shared Google Doc + some sort of whiteboarding app) for 4 hours, which I suppose counts as a success. We got a lot of design work done, anyway.
Digging through old todo lists, I just deleted the "make ls sometimes exit with 2 instead of one" patch from a 2019 thread out of my main toybox work directory. There's a certain amount of accumulated shoveling out I've needed to do...
January 9, 2022
Sarah Taber Tweeted about Harry Reid far more charitably than I feel about him. I think justice delayed is justice denied and it's far easier to stall popular things forever than openly oppose them. I think that Harry Reid and his ilk are "good cop" on behalf of the plutocracy, endlessly saying that the suspect being questioned needs to give a little more cooperation and then MAYBE he can help afterwards, once the cops have a full confession signed in blood and you've pled guilty to something you didn't do and served your full life sentence without parole at a for-profit prison where you work without pay for your new owner.
Taber explains how when she was growing up the mormon church told people they were going to hell if they didn't vote solidly republican (and somehow kept their tax exempt status while doing this), and Harry Reid being a prominent mormon Good Cop instead of Bad Cop was a big deal. So his existence was apparently useful in very slightly pushing back against a persistent refusal to enforce existing laws against the rich and powerful fifty years ago. He then spent his entire career blocking progressives from doing anything useful via spineles equivocation and delay and lip service plus strategic incompetence. ("We tried but couldn't get it done, sorry, maybe next time, just a little more and then maybe I can help get you the pie I'm holding up in the sky someday".)
Note that Reid stayed around blocking change well past what USED to be normal retirement age essentially died in the saddle, only finally retiring because at age 75 he fell and broke multiple bones which is how they found the cancer he died of. Reid was 100% part of Nancy Pelosi's gerontocracy that exists to prevent AOC and friends from exercising any real power. Diane Feinstein is coming up on 90 and her memory is gone but like Ruth Bader Ginsberg she is determined to die in office because she's SPECIAL and nobody else could ever possibly do her job, which is hers by divine right for life. (That last article points out the republicans have switched to rotating committee heads, but the democrats use pure seniority and all their leadership is in their 80s. Chuck Grassley is EIGHTY EIGHT YEARS OLD and president of the senate. Pelosi is 81 and speaker of the house. The president they serve turns 80 this year. THIS IS NOT NORMAL. Nor is it remotely effective at addressing any of the real problems we face.)
January 8, 2022
LWN had a good example of why DLL hell (too many package dependencies) is terrible.
Trying to do toybox video scripts (the "write down what words to say in which order" kind) involves inspecting a lot of code I haven't looked at in a while and doing lots of little cleanups. It's the old problem that writing documentation results in changing the thing you were trying to document to be easier to explain.
I have a large pending change to lib/passwd.c including basically a rewrite of update_password() that changes the number of arguments it takes (by specifying which field "entry" replaces). Of course if I change the arguments to a lib/ function, I have to change every user simultaneously in order to check it in without breaking the build, and in this case that means updating the commands passwd, chsh, groupadd, groupdel, useradd, and userdel.
Except only "passwd" has been promoted out of pending, and even that one was kind of a stretch: it was merged back before I had a pending directory yet. I did some cleanup but didn't have proper test infrastructure for any of the /etc/passwd stuff. I'm just now getting there with mkroot.
The backstory on this plumbing is that way back when busybox didn't trust libc to implement it, possibly because uClibc was crap. And these days glibc has decided all access to /etc/passwd go through Pluggable Authentication Modules via dlopen() and thus statically linked binaries can't do this basic stuff either, and of course android installed each java applet as a seperate UID 15 years ago (before spraying the system down with SELinux rules and more recently adding container support), so bionic never implemented conventional posix user/group support. (Well, they've started recently except if you build toybox with the NDK and run "make tests" you get a bunch of "libc: Found user/group name 'root' in '/etc/passwd' without required prefix 'system_'" error messages... so no, this doesn't work there either.)
So I guess I should finish this and use it consistently. And doing so fishes 5 commands out of pending in one go, which isn't bad. And it's good to have in mkroot.
Hmmm, these commands should consistently support -R to work in a chroot, which means they can't use the library getgrnam() and friends with hardwired paths at _all_. (Which again: if we could, we should, so the reason for doing the x:y:z line parsing ourselves is because libc isn't reliably load bearing.) Right now the command implementations are mixing them, which can't be right...
Does this mean EVERYTHING should be using the new ones and not the libc ones? Hmmm. I got xgetgrnam() wrappers already, I could redirect it to new plumbing but... What's the right thing to do here?
I've had passwd compiling in my tree against the new lib functions for a while. Just got chsh and groupadd compiling again, but need to clean out the libc passwd/group/shadow functions from them still...
I note that lib/pending.h only has the lib/password.c stuff left in it, so I need to move stuff out of there and delete that. One more corner case: pending.h has #define MAX_SALT_LEN 20 and that seems kinda disgusting. I'm tempted to just use 32 in the callers? I don't have a #define for the scan_key() scratch buffer, which is something like strlen() of the longest scan_key_list entry plus a null terminator, and I've just been using 16 because it's power of 2 plenty long enough. That's kind of what I want to do here, but... is having the #define for a magic constant sillier than having the callers use magic numbers? Hmmm. (This also argues for static buffers. It's another one of those "the fighting is so vicious because the stakes are so small" things; if it was important the answer would be more obvious.) I should stick a TODO note about this somewhere, especially since I'm redoing the tty stuff at the moment anyway. This dirties mkpasswd.c (which calls get_salt() and thus uses MAX_SALT_LEN).
Ok, once I've got everything going through again, I need to git commit lib/{password.c,pending.h,lib.h} toys/*/{passwd,chsh,groupadd,groupdel,useradd,userdel,mkpasswd}.c. Right. (With a sufficiently dirty tree, tracking checkin batching and then testing it in a clean directory is one of the big scratchpad things I need to track. I'm aware tools like "git stash" exist to help this, but I've never managed to use them in a way that caused me _less_ work.)
January 7, 2022
Moxie Marlinspike's article about web1 being distributed and web2 being centralized (and web3 being a scam) is the same problem I'm dealing with putting a "video" directory under the toybox website: the bandwidth I can afford won't survive becoming popular, and the hosting service will REMOVE it rather than let it get whatever they call slashdotted these days. Napster inspired bittorrent to solve the scalability issue, but our pathologically broken intellectual property system attacked distributed solutions as "capable of being misused".
And yes the Boomers are going after cash now under the same "logic". Coins could be used to buy drugs or child porn or sex trafficing or something, therefore nobody can have coins anymore, all financial transactions must be reported to a central authority in realtime that authorizes or denies them based on whether it's a moral use of the funds, and while we're at it that central authority isn't even the state it's a monopsony of private for-profit corporations and the good-or-bad judgements are made by the collective advertising decisions of every other corporations' sales departments. Oh just FILLS me with confidence that does. This is motivating crypto-loons to do digital goldbuggery because "we senile chronically lead-poisoned Boomers can't be trusted unsupervized, therefore nobody can!" is not a sustainable position. Emergent populist solutions are often worse than the problem, but suppressing populism via police state has never ended well for any government. (The KGB had every phone tapped in Russia, the Stazi had it in germany, China's doing it now and the wheels are coming off over there. Not new, but authoritarians are always SURE that the problem is the lid of the kettle isn't screwed down tight enough. Here's a system built by people and run by people that people can't escape, this time for sure! Interesting times kinda suck.)
Capitalism's been "the state" doing the fighting back against non-monetizable individualism for decades, and it's capitalism screwing up distributed solutions to problems. Bittorrent was blamed for slowing networks when the problem was actually bufferbloat (a problem crunchyroll's servers still stuffer from enormously). I could totally post a torrent tracker on my site and it would scale, but no browser will view said video when pointed at a torrent because it might be pirated! It's not centrally controlled and audited, it could be used naughtily! You aren't to be trusted! (The raw link to the mp4 file could have exactly the same content, but that doesn't scale and thus isn't a threat to "pay me to keep breathing" business models demanding endless growth.)
The entire "right to repair" movement needs to exist because capitalism's drive for endless growth (we are insanely profitable very year and it's NOT ENOUGH, unless we make MORE MONEY THAN WE DID LAST YEAR we have FAILED) always tries to corner the market. For me to win, you must lose. That's where it comes from, and it is HIGHLY destructive.
The return to school despite omicron is because day care is necessary for parents to return to work. It serves no other purpose. People are dying, the CDC only cares about profit.
As always, the solution is A) the Boomers die, B) fix everything afterwards.
January 6, 2022
Anniversary of the insurrection and Garland has indicted nobody. They're pardoning Nixon again via statue of limitations, with the occasional half-assed finger shake. About what you'd expect from septuagenarians.
Dialed into the posix teleconference this morning, and the issue they're arguing about seems... irrelevant? It's great to specify it but from my point of view I need a test case and to see what bash does, I'm never going to usefully extract it from posix legalese. (And I'm pretty sure I already DID check this stuff when I was implementing here documents, and matched what bash did at the time.)
Yes, cut -DF is being discussed on the coreutils list, no I didn't bring it up on the call or on the posix list, because doing so can only hurt, not help. There's enough bikeshedding as is. Speaking of which, so I did NOT send the following reply email (which is somewhere between "selling past the close" and "stirring up a hornet's nest unnecessarily"). Served better by silence I think, but for the record:
On 1/6/22 8:35 AM, Pádraig Brady wrote:
> Thanks for taking the time to consolidate options/functionality
> across different implementations. This is important for users.
Thanks. The Android maintainer asked me to. :)
> Some notes below...
>
> On 05/01/2022 16:23, Rob Landley wrote:
>> Around 5 years ago toybox added the -D, -F, and -O options to cut:
...
>> This lets you do:
...
>
> Cool. I agree that the functionality is useful,
> especially in places where awk may not be available.
>
> As I see it, the main functionalities added here:
> - reordering of selected fields
Disabling the reordering to maintain literal order was suggested to posix years ago. Technically this option makes cut do _less_ work. :)
> - adjusted suppression of lines without matching fields
-D implying -s wasn't strictly necessary, but I couldn't come up with a use case for -D without -s. The awk behavior this replaces doesn't pass though lines without matches verbatim, grep -o doesn't have an option to pass through lines with no matches, and if "cut -DF" seems long "cut -DsF" is longer...
> - regex delimiter support
>
> I see regex support as less important, but still useful.
I tried to implement it without regex support first, but switching from handling "characters" to handling "strings" is inherent in the problem space, which gets us most of the way to regex already.
As soon as you switch from single character delimiter to "run" of whitespace (which could be mix of tabs and spaces, plus all toybox commands handle utf8+unicode so mine has to cope with half-width spaces and ogham non-blank whitespace and such), you're confronted with the need to set a default output delimiter because your field delimiter isn't guaranteed to be the SAME run of whitespace between entries, and there's no "before first match" or "after last match" to pass through anyway. I even tried options like "pass through first input delimiter as first output delimiter" but it REALLY didn't help: you can repeat output fields so you run out of input delimiters (what, rotate through again?), the result was just magic nonsense with no obvious relation between delimiter and output field (echo one two three | -cut 2-3 would use the delimiter between 1 and 2), and of course "echo hello | cut -F 1,1" has literally NO delimiters but should have obvious behavior.
If you hardwire in "single space" as your output, you wind up converting tabs to spaces, so it has to be an overrideable default. I basically wasn't smart enough to figure out how _not_ to do -O with a default value, and the existing --output-delimiter was a string, at which point both input AND output are "string not char".
Another need for regex (other than not wanting to special case "run of whitespace" when "regex" was right there) is that it's not parsing escapes, so if you DO want to support "abc\ def ghi" as "abc def" then "ghi", cut paying attention to that would be policy. The user deciding what is and isn't a separator via arbitrarily complex regex magic (a skill that exists out there and is Not My Problem if I just pull in something libc already has) _isn't_ policy...
>> P.P.S. -D implying -F doesn't help because -F is the one that takes arguments,
>> analogous to -f.
>
> As for the interface,
I try to get bikeshedding out of the way up front on this sort of thing, so back in 2017 I asked for feedback about the pending cut changes on the toybox list. Unfortunately -DF looks to be in one of the Dreamhost Incompetence holes:
http://lists.landley.net/pipermail/toybox-landley.net/2017-October/009196.html
But here's an adjacent cut issue from the same update batch:
http://lists.landley.net/pipermail/toybox-landley.net/2017-October/009214.html
Elliott suggested I poke other projects for compatibility reasons so what we already deployed isn't an outlier, and I started with busybox because I have a history there. That's why I asked here if coreutils wanted to be a third compatible implementation for something already used by a bunch of android package builds and shipped in a billion Android devices a year for the past 4 years. Coreutils implementing a different interface is another way of saying "no, we don't want to be compatible with this", which is of course your call.
But sure, "As for the interface..."
> it's a bit surprising that -F wasn't used to
> switch the field handling mode, rather than -D.
Lower case -f is single character fields and upper case -F is regex fields. Both -f and -F take the same comma separated numeric argument lists and do approximately the same things with them, just using different delimiters. Using -f and using -F are analogous, and -F by itself preserves the old reorder/passthrough behavior just with regex separators, because that's what -f (still) does.
-D was "Don't reorder". It's logically separate.
If you're saying that -D and -F shouldn't have been separate (using -F should have the side effect of -D), that's what I tried to implement first and I hit multiple snags, only some of which are mentioned above.
Not only is -F useful by itself but "cut -d. -Df 3,2" seems a reasonable thing to do, which with forced regex would be 'cut "-d[.]" -DF 3,2'. Or with no -D and -F being "magic run of whitespace" how would you "cut $'-d\t' -Df 3,2" to use tab separators that DON'T collapse together? With separate -D you can ask the existing -f not to reorder.
(Yes, there is still an existing -f, why _can't_ it do this too?)
> I.e. I see the mode
> change more pertaining to field handling, rather than delimiter handling.
You haven't tried to implement it or made nontrivial use of it.
> I don't have a strong opinion on this, but it may be a bit confusing to users.
I tried implementing one argument instead of 2 and it was _more_ confusing because of the multiple magic implied behavior changes. Giving the user less control isn't the unix way, and while "sane defaults" is an excuse for -F to change the -d and -O default values (both of which you can override so no control is lost), having -F imply -D if -f doesn't is inconsistent, and trying to have -D toggle the state BACK means the mnemonic "Don't" is enabling the behavior in one case but disabling it in the other case... Yes I considered that, it was icky.
I could not disturb historic behavior of existing options, so the new feature wound up a little verbose to be consistent, but less verbose than "--df 1,2,3" would have been while providing more control.
Given a choice I'd have had -s be the default behavior all along, had -D be the default behavior all along, and had -F be part of cut 40 years ago. I didn't get to make that call, I had to modify what's there in a way that made sense in context.
> BTW it's useful to note existing edge cases in delimiter handling
> when considering this new interface:
> https://www.pixelbeat.org/docs/coreutils-gotchas.html#cut
Let's see...
1) "cut doesn't work with fields separated by arbitrary whitespace. It's often better to use awk..."
Isn't that what this new feature directly addresses? The fist "edge case" is that coreutils' cut implementation doesn't have this feature yet. Um... yes?
2) "Similarly, if you want to output a blank line when there are no delimiters..."
Your other edge case is that passing through lines with no delimiters is an inconvenient behavior people would like to suppress. Cut added -s instead of adding a "turn them into blank lines" option.
> So to summarize the new interface, and how it might map to / be described in coreutils,
> I see it as:
>
> -F, --regex-fields=LIST
> Like -f, but interpret -d as a regular expression (defaulting
> to a run of whitespace)
> -O,--output-delimiter=STRING
> use STRING as the output delimiter
> default is one space with -F, or input delimiter for -f
For reference:
$ toybox --help cut usage: cut [-Ds] [-bcCfF LIST] [-dO DELIM] [FILE...] Print selected parts of lines from each FILE to standard output. Each selection LIST is comma separated, either numbers (counting from 1) or dash separated ranges (inclusive, with X- meaning to end of line and -X from start). By default selection ranges are sorted and collated, use -D to prevent that. -b Select bytes -c Select UTF-8 characters -C Select unicode columns -d Use DELIM (default is TAB for -f, run of whitespace for -F) -D Don't sort/collate selections or match -fF lines without delimiter -f Select fields (words) separated by single DELIM character -F Select fields separated by DELIM regex -O Output delimiter (default one space for -F, input delim for -f) -s Skip lines without delimitersIf you add --longopts for the other two I can add them to toybox to be consistent.
> cheers,
> Pádraig
Rob
January 5, 2022
December and January are recruiter season (everybody's annual budget renews and there's a scramble to spend it), and although I haven't been looking (working for Jeff and waiting to see if Elliott's boss can get budget to pay me to focus on toybox this year), but the game 7 recruiter came up with something interesting enough I agreed to a phone call with the engineers, and that turned into an offer at the same "pay off the mortgage fast" rate I made at JCI, and then when I said I'm probably too busy to do it they upped it $10/hour and made the initial commitment only 3-6 months. Really hard to say no, but also not what I want to do with my life?
I forwarded the offer to the Google recruiter with a request that if the 6 months of "maybe" are going to turn into 9-12 months of maybe, could he let me know so I could maybe fit this in first? Except I'm working for Jeff this month, so I'm probably saying no either way. But wow, it's tempting.
Had the call with the recruiter. He kept trying to get me excited about using "20% time" on toybox, and spending the other 80% on some other Google project. He wanted to get me excited about one of the opportunties he had. Sigh.
I tried to explain to the Google recruiter how my old distro build work led me to wanting to untangle the AOSP build, so if the job was working on the AOSP base build it would at least be heading towards the mountain, but he really didn't have the backstory to understand it. (I pointed him at my 2013 and 2019 videos again. Doubt he watched them, not really his job.)
But yes, I need to learn how to disentangle AOSP and repot it on top of mkroot and merge the NDK and AOSP toolchains and... poking around in that area would serve my purposes. Except Google isn't hiring me to serve MY purposes, and all the big corporate types only believe infrastructure is going to exist after it already does exist. (There's no such thing as a good idea, only a good time-proven historical implementation. Anything that doesn't exist yet is a fantasy, and anything that already exists was inevitable and happened without their help, QED.) And apparently every Google recruiter sees me and goes "He breaks everything and has thus spent decades learning to debug every problem thrown at him since age 12? Site Reliability Engineer!"
Poked the coreutils list about "cut -DF". Did not directly reference poking the posix list last month, but if we get the feature into coreutils, busybox, and toybox it's a de-facto standard anyway. (I could also poke the freebsd guys at that point, and... is there still any kind of open source darwin effort?)Busybox added sort -h the day after I yanked it for being badly defined, so I've pinged their list but I'm not 100% sure what question I'm asking. If Busybox had implemented the sane behavior I'd probably use it as leverage to make puppy eyes at coreutils and see if THEY might change, but nope, busybox is blindly doing what coreutils did because it's better to be compatible than make sense.
$ echo -e 9999999K\\n1M | sort -h 9999999K 1M
I suppose I could say I'm waiting for posix to add, that's a solid excuse NOT to for a couple decades.
Hanging out in the new office space Jeff arranged. I haven't got a 24 hour access card yet, and they can't GIVE me one without a dedicated desk, their "lounge access" plan doesn't come with a card. I have to show ID at the desk during 8:30am to 5pm business hours, but then they let me stay after the staff leaves. I can't get back in after that, but there's electricity, wifi that doesn't drain my tethering quota, nearby bathroom, hot water tap I can make ramen with, no mosquitoes so far and I have yet to encounter a bug flying into my can of caffeine (easy to prevent if you drape the mask over the top when you take it off, but it's still a concern), it does NOT get down well below freezing where I'm sitting (although that largely counters the flying insect issues; the raccoons going through the trash cans are tame and fairly polite but again none inside here so far), and if the UT carillon spends 12 minutes playing "I've been working on the railroad" twice over very slowly at 9pm I don't have to listen to it. The downside is the occasional unmasked white male Bro playing ping pong, but so far only during business hours.
(Yes, I know the filk lyrics the school uses: "The eyes of texas are upon you all the live long day, the eyes of texas are upon you you cannot get away, they follow you when you are sleeping and in the bathroom too, the eyes of texas are upon you there's nothing you can do. Hook 'em." I'm aware those last two statements seem contradictory, but that's sportsball for you.)
I'm trying to set up a debootstrap to do a clean toybox build in for an introductory video, but "apt-get install git-core" is trying to install 40 new packages, including perl, libx11 and xauth (a gui), krb5-locales (the kerberos locales packages)... Define "core" please? I can install the "git" meta-package and chose NOT to.
January 4, 2022
Mozilla has fallen so far even its founders are speaking out publicly against it.
Fuzzy left a cup of water right next to my laptop on the dining room table, and Peejee predictably did her thing, and I had to pull the battery out of my laptop for 2 hours while it dried off. (Alas, prevented me from heading out to the Philbin before it closed.) Lost all my open windows, but it otherwise SEEMS ok so far? (And I have 3 other instances of this hardware I bought and can swap the disk and memory into if necessary, but it's a pain.)
Oh goddess, I yank "sort -h" from toybox for being badly defined, and the next day busybox adds it. Strongly suspect we got pinged by the same guy asking for the feature. And he matched the "12345k is less than 1M" broken behavior that I AM NOT DOING. So do I put back the one that's correct rather than conforming, or do I leave it out? Hmmm...
The Google recruiter resurfaced and said "I chatted up Lars and got an understanding of the situation. I think we have the space to make this work. Let's jump on a call this week, it's easier to explain on the phone." Which... I want him to succeed? I really don't care what budget this comes out of as long as I get to do the work? But I've been bait-and-switched a LOT over the years.
I like vaguely threatening nudist winnie-the-pooh so far.
January 3, 2022
Oh hey, Harry "dishrag" Reid (D. Spineless) died and the very next day the Senate is on a deadline to vote on removing the filibuster so they can actually start getting stuff done. Change really DOES happen over Boomers' dead bodies. While still warm.
First day back working for Jeff on J-core stuff. He's trying to get office space in the "Regis" at the Dobie, but it's not ready yet, so I'm working from home, and from HEB, and from the table outside the UT Geology building...
I've circled back around to trying to track down why the mkroot boot process on turtle isn't completing properly. It seems to be something to do with the nommu error path for redirecting a file that doesn't already exist? Unfortunately this sucker is heisenbugging all over the place (change something seemingly unrelated and the bahavior is entirely different), which makes debugging it in chunks hard. Come back and you can't even necessarily reproduce where you left off because you misremembered something insignificant and it went "boing". Probably not uninitialized memory. Could be a misaligned read somewhere. But CURRENTLY it looks like the redirect logic trying to save an "old" filehandle that wasn't open records that fact wrong so the "undo" logic is damaging the filehandle state, which presumably isn't the initial problem but makes debugging way harder.
I need stdin/stdout/stderr to WORK in order to see what I'm doing, and the problem is my patches to fix this in the kernel got rejected, so there's an early userspace dance which is failing and I can't see WHY it's failing. I thought there was some way to syslog() data into printk() so it winds up in dmesg and globally written to /dev/console if the priority is high enough, but I think it's actually something you write into under /proc or /sys which doesn't help with early logging before I've mounted anything.
January 2, 2022
Ooh, no. That's not... No. Yoink. I'm sorry, "sort -h" is just BADLY DESIGNED if that's the expected behavior.
Working on scripts for explanatory toybox videos. The more I sit down and think about it, the more material there is to cover. Pascal's Apology indeed...
I've been referring to them as "youtube videos" but I'm not entirely convinced youtube is the best place to post said videos. Youtube has had chronic issues that are somehow managing to get worse. Most videos for the past couple years have a musical outro so people can upload said outro to spotify and copyright claim their own video so that when someone ELSE inevitably spuriously claims it you at least SHARE the revenue during the dispute period rather than losing all of it. (Because they get the revenue while they've claimed it, and if you win the dispute you just start getting new ad views deposited into your account, you don't get the old money BACK, they get to keep it. And most videos see the majority of their views in the first few days after upload, so the spurious claim may take away most of the views this video ever gets.) I'm not posting these for youtube ad revenue, but even if you upload public domain footage from nasa it gets claimed. And then there's youtube running more and more ads on less and less content, and hiding non-monetized videos, and publicly stating the intention to annoy viewers into subscribing (except paying for youtube wouldn't get the content pandering to advertisers has driven off youtube back because it's not on youtube anymore)...
Can I just post videos directly to patreon? Hmmm... no, but when patreon explains how to link videos from their service, youtube is not one of the suggestions. They seem to have teamed with vimeo? Worth a try...
Eh, first I need to record it. I can post the mp4 to a temporary directory on landley.net to get feedback. Really what I want to do is have landley.net/toybox/video with an index file, but that doesn't scale to lots of simultaneous viewers. (You'd think it would by now given 9600 baud ISP dialup in 1993 turning into my 2 gigabit/second google fiber home connection in 2022, but capitalism got in the way.)
January 1, 2022
Redoing the tty plumbing, and I'm trying to figure out if tty_esc() and friends actually simplify anything? In theory you can just printf("\e[%u;%uH", y+1, x+1) but tty_jump(x, y) kind of acts as documentation, and reminds you that the argument order is swapped, and does the +1 for zero-based coordinates. Is that a win? I've been converting hexedit.c to not rely on the tty_blah() functions for color changing and stuff and just output them with printf("\e[blah") itself, but the result has conversions like:
- tty_jump(0, TT.rows);
- tty_esc("K");
- printf("\e[1m%s: \e[0m%s", prompt, TT.input);
- tty_esc("?25h");
+ printf("\e[%dH\e[K\e[1m%s: \e[0m%s\e[?25h", TT.rows+1, prompt, TT.input);
Which... works fine? But is kinda incomprehensible. But then how comprehensible was it before? Is this actually a win?
I'm pretty sure that:
- tty_esc("?25l");
+ printf("\e[?25l");
Is a win? I tried to have a tty_color() at one point but the real question is "which color is 32, and does that set foreground or background color" and I'm NOT making a stack of enums for this.
Maybe I need to link to the "man 4 console_codes" web page at the top. Except... in every command that uses it? In lib/tty.c?
(Toybox development is always like this. It's a lot of work to come up with a simple result because it's hard to define "simple", and you only ever get a local peak anyway. I should have called it dorodango because it's endless polishing.)